Parallel Sets
Una visualización para datos multidimensionales categóricos.
PID_00233252
Autor: Álex GonzálezCoordinación: Julià
Minguillón
Los parallel sets son un tipo de visualización orientado a la representación de datos multidimensionales categóricos; es decir, donde cada variable o atributo solamente puede coger un valor en un conjunto finito (y habitualmente reducido) de valores o categorías. El objetivo es comparar las frecuencias de aparición de cada valor posible; se pueden comparar también relaciones entre atributos. Es una buena representación para tablas de contingencia multidimensionales, puesto que permite ver el desglose de combinaciones posibles para un conjunto de datos dado. De hecho, se trata del equivalente a visualizar los agregados del conjunto original, otra técnica conocida como parallel coordinates.
La estructura de una visualización usando parallel sets es la que se muestra a continuación. Los atributos se ordenan (de hecho, apilan) habitualmente de forma vertical, usando la frecuencia de aparición de cada valor posible para cada atributo como tamaño horizontal. El orden de los atributos (verticalmente) y de sus valores (horizontalmente) puede cambiarse indistintamente para destacar diferentes combinaciones de atributos y/o valores. Para cada valor posible dentro de un atributo, se puede usar un color diferente, para resaltar las combinaciones de valores entre atributos, usando normalmente tantos colores como valores posibles pueda coger el primer atributo.
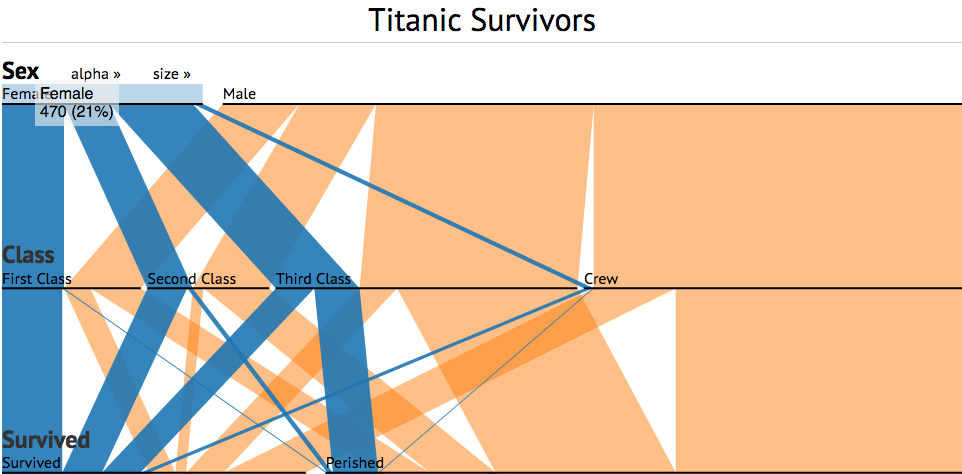
Este ejemplo, de Jason Davies, muestra la relación entre sexo y la clase en la que viajaban los pasajeros del Titanic con el hecho de sobrevivir o no al accidente. Se puede ver claramente que casi la totalidad de mujeres que viajaban en primera clase y la mayoría de las que viajaban en segunda clase se salvaron, mientras que el porcentaje de supervivientes entre las que viajaban en tercera clase es inferior al 50%. Sin ningún cálculo, es posible observar hechos que pueden resultar interesantes para un análisis posterior más detallado.
La siguiente visualización muestra como usar parallel sets para visualizar un conjunto de datos categórico; en este caso se trata de datos provenientes de una encuesta realizada a los estudiantes del máster de Business Intelligence de la UOC, contestada por ciento cuarenta personas. Los datos han sido procesados para eliminar valores perdidos, y agrupados para reducir el número de categorías con muchos valores posibles (bajo "Otros").
Los atributos de los cuales se dispone para cada participante en la encuesta son los siguientes:
Para cada dimension o atributo, se muestra una barra horizontal para cada uno de los valores posibles que puede coger. La anchura de la barra es proporcional al número de elementos que toman dicho valor.
Empezando por la primera dimension («Sexo»), cada una de sus categorías o valores posibles está conectado con las del nivel siguiente, mostrando cómo dicha categoría se subdivide. Este proceso se repite en cada nivel, produciendo una especie de árbol de «cintas» cada vez más delgadas en su extremo inferior.
Es posible arrastrar tanto las dimensiones como las categorías, reordenando la visualización. También se puede hacer clic en los enlaces «alpha» y «size» dentro de cada dimensión que aparece al poner el ratón encima, para ordenar los valores posibles alfabéticamente y por frecuencia de aparición, respectivamente, tanto ascendente como descendentemente.
Para finalizar, es posible visualizar las «cintas» como líneas rectas o curvas, mejorando la visualización en algunos casos.
Como se puede ver en la visualización (poniendo el ratón encima de cada valor), el porcentaje de hombres (78%) triplica al de mujeres (22%). De la misma forma, el porcentaje de mujeres entre 35 y 44 años es del 9%.
Reordenando los valores de la dimensión «edad», se puede construir la tabla de contingencia de 2 × 4 siguiente:
| Sexo / Edad | ≤ 24 | 25-34 | 35-44 | ≥ 45 | Total |
| Masculino | 3 | 50 | 40 | 16 | 109 |
| Femenino | 2 | 12 | 13 | 4 | 31 |
| Total | 5 | 62 | 53 | 20 | 140 |
Arrastrando la dimensión «Intereses» hasta la segunda posición, por debajo de «Sexo», se puede ver que, en el caso de las mujeres, estas tienen un menor interés en los aspectos técnicos de Data Science. De igual forma, también menos mujeres disponen de una cuenta en Twitter.
En general, la visualización muestra una tabla de contingencia de la dimensión 1 × la dimensión 2 × la dimensión 3 × ...
Como se puede observar, si el número de dimensiones es elevado, las «cintas» cada vez son más finas, pudiendo incluso desaparecer para alguna combinación de valores en concreto.
Igualmente, si el número de valores posibles o categorías para una dimensión es también muy elevado, se produce una fragmentación excesiva y resulta complicado visualizar las combinaciones de las dimensiones inferiores.
De hecho, la visualización hereda los problemas de las tablas de contingencia multidimensionales, donde no es habitual exceder de cuatro dimensiones, ni que para una dimensión dada haya más de seis valores. Un regla empírica para el análisis de tablas de contingencia es que ninguna combinación de valores generada (es decir, cada celda de la tabla) debería estar vacía (es decir, 0 elementos), y que la mayoría de las combinaciones (al menos un 80%) debería tener cinco o más elementos. Nótese que el ejemplo propuesto no satisface casi ninguno de estos requisitos, de ahí su complejidad.
No obstante, la visualización usando parallel sets permite hacerse una idea rápida de la distribución de valores para cada dimensión y de las combinaciones más frecuentes; es mucho más intuitiva que una colección de tablas de contingencia multidimensionales, especialmente si, como en este caso, es posible reordenar de forma sencilla dimensiones y valores.
Esta visualización consiste en una página HTML (enlace) que incorpora código D3.js ( enlace) y puede ser utilizada como base para reproducirla usando cualquier otro conjunto de datos.
Es necesario disponer de las librerías d3.v3.min.js (v3, descargable también desde D3.js) y d3.parsets.js (descargable también de Jason Davies' parallel sets), las cuales deben estar en un subdirectorio llamado js dentro del mismo directorio de trabajo que la página web mencionada.
El fichero CSV que visualizar debe ir separado por comas «,» y utilizar una codificación UTF-8. El fichero usado en este ejemplo puede descargarse desde este enlace. Se recomienda utilizar LibreOffice para su manipulación.
El fichero parallel-sets_base.js que contiene el código D3.js puede ser modificado para reutilizar la visualización con otros ficheros CSV, de la manera siguiente:
@import url(d3.parsets.css);importa la hoja de estilo que determina los colores y fuentes utilizados en la visualización. Es posible editar el fichero d3-parsets.css para modificarlos.
var chart = d3.parsets()
.dimensions([«Sexo», «Edad», «Nivel de estudios», «Sector», «Perfil»,
«Windows», «Intereses», «Twitter», «Inglés»]);
define los nombres de las columnas que intervienen en la visualización, los cuales deben coincidir con la primera
fila del fichero CSV exactamente. Es posible reordenar las dimensiones para establecer la visualización inicial
por defecto.
d3.csv("./data/PEC0_20152.csv", function(error, csv) {
es la que carga el fichero CSV desde su ubicación y genera la visualización.Se propone simplificar la visualización mostrada como ejemplo, reduciendo el número de dimensiones por mostrar, así como el conjunto de valores que puede coger cada atributo o dimensión en aquellos casos que sea necesario.
Por lo tanto, es necesario:
Materiales creados por Álex González (outliers) y Julià Minguillón, publicados bajo una licencia Creative Commons CC-BY-SA 3.0, Universitat Oberta de Catalunya (FUOC), 2016.